[This essay was included in every Wide Area Information Servers (WAIS) distribution as a way to instruct server operators (later to be called webmasters) on how to deal with log files. Software distributions can be found https://archive.org/details/freeWAIS-sf-1.0
I am proud of this essay. It seems prescient -brewster]
Ethics of Digital Librarianship Brewster Kahle Thinking Machines February 1992
“As digital librarian, you should serve and protect each patron as if she is your only employer.”
As more of us become involved in serving information electronically to other users, we so-called “digital librarians” must become conscious of our ethical responsibilities to protect the privacy of our the users being served. Since computers are being used by many more people to find answers from diverse information sources, we librarians that operate these servers are coming exposed to the exact questions and interests of people we do not know. This information has power, a power that can be abused and thereby thwart the usefulness of the tools we promote. In this essay, I will use the Wide Area Information Server system as an example of a system of digital librarians to show what information is collected and used. With this example, I hope to illustrate some of the dangers and help list some of the rules of etiquette for this emerging class of information providers.
The Wide Area Information Server (WAIS) system is an electronic publishing system that allows end-users to ask questions of remote information sources. The system encourages people to ask questions in natural language so that the server system can try its best to find appropriate documents. Therefore the operator of the server can collect the questions, and importantly, collect what documents the users thought were worth looking at. This combines to portray exact interests of the users. While the identity of the user is not trivial to determine since only the machine that the query came from is accessible from the server logs, as personal computers become networked, the identity of the machine will approximate the identity of the user.
On the positive side, this means that the server operator (the “digital librarian”) can use that data to refine the database and the search techniques used in the system. On the negative side, this is exposing many remote operators to private information that may not be consciously given by the users.
This surrender of information is not new to librarians; and the responsibility is taken very seriously by the professionals in the field. Through training in library schools and by an intuitive sense of ethics, reference librarians do not betray their patron’s interests to others that are curious or devious. This ethical code is not coded in law as it is with psychiatrists, so these records can be extracted through subpoena, but this level of demand is usually required to pry the information from librarians. From the patron’s point of view, having a librarian know what she is interested in can be a great value because the librarian can help select and route useful information in the future.
The same type of information is available to the digital librarians of the WAIS system. I operate the directory of servers in the WAIS system, and as such, I know what users are requesting access to what type of servers. I know, for instance, every time Mitch Kapor uses the system, and what he asks for (he specifically allowed me to include his name here). At this point this is not a problem since few servers are of a personal nature yet, but as the system grows to include entertainment, employment, health and other servers, it is easy to imagine the types of information that will be accessible through operating such a server. Furthermore, I know when particular users are at their machines, and therefore know where they are and when.
The abuses possible with this information are often not as direct as other offenses, but should not be discounted. People will act differently if they think they are being watched. Most people will try not to look silly or ignorant in public, and therefore might be less willing to try something new, to learn about a subject that they know nothing about. If using a WAIS server feels like raising one’s hand in school, then people will craft their questions more carefully than if it felt more like browsing through a new book. Often people say “I have nothing to hide,” which may be true, but if a stranger approaches on the street and knows quite a bit of personal information, then the innocent will likely take that person more seriously than if a cold stranger approached. Even with nothing to hide, most people feel they should who knows what about them. The personal nature of information access makes distributing collected questions a bit unnerving.
The information collected by the digital librarians have some different characteristics from physical librarians which can make abuse easier and more widespread: more people can be served, these people are often in other organizations, and the digital librarians rarely have personal contact with these users. Therefore, the patrons seem further away and therefore less real as human beings. Since the computer networks that are being used with WAIS span the globe and span company boundaries, the information collected can be useful in knowing what is important to a distant, and possibly competitive group. The lack of human contact can lead to the decay in social relations as has been documented in studies of electronic mail where the language and nature of relations tend to be stripped of grace, etiquette, and often respect [cite Sherry Terkle]. This detached nature of electronic interaction might lead librarians to not respect their patrons’ interests where they would if they knew them personally.
On the other hand, the information collected from patrons can be very useful to the digital librarian to refine and enhance the server. An example of this is a reporter at a financial newspaper. She is in the business of collecting information from corporate contacts, finding the trends in that information, throwing out the proprietary details, and selling it back to that same population. If the reporter published too many details, then her contacts would not be forthcoming the next time, and if she sanitized the information to the point of uselessness, similarly, her contacts would not invest the time. Therefore, it is precisely the interaction with the users that builds the information that is sold. This example shows another facet, and that is value that the contacts invest in the reporter for their own benefit. The digital librarian is a less extreme case, but still she is being invested and entrusted with what the users want, and if this information is misused or not used, then the users will not be as well served as could be. Thus, the users will want to be able to be served better by the librarian through feedback on services rendered.
While there are some technological mechanisms to obscure the identity of the patron, such as encryption and redirection, hopefully these will only be used in extreme cases. Encryption can be used to protect packets in transmission and also be used to sign packets so that they can not be forged [cite Whitfield Diffie]. This can be useful in a system where the transport media is insecure, such as radio transmission. Redirection is a server forwarding technique that would concentrate all the requests from one trusted host so that the individual requesters are more difficult to determine. Combinations of these techniques have been contemplated to provably obscure requesters while still providing accountability for charges, but hopefully these techniques will not be the norm if most server operators will act in good faith towards their patrons.
To try to list a code of ethics for this field is difficult since the technology keeps changing, but I will offer a principle that can be used to test a code. As digital librarian, you should serve and protect each patron as if she is your only employer. Therefore each patron should be served and protected individually. In terms of WAIS, I feel it is safe to suggest:
Don’t give away user logs except for scholarly use. Consider sanitizing the records before any transfer is undertaken.
Take the job of information serving seriously. This means to provide a consistent, reliable service and represent the service provided accurately.
Count on wide use of the information served, for good uses and bad, so be proud of the information and the collection.
Completeness is important. Users learn as much from a question that has no answer as from the ones with answers. This requires a complete and up-to-date collection.
Assume that the patron will not know the your affiliations, and therefore do not tempt patrons to use a service they would regret if they new more about you.
Respect your patrons. The opinion that users are “rocks with arms”, as said by a colleague years ago, will not lead you to become a very helpful digital librarian.
In conclusion, the rewards from being a digital librarian are numerous and can be evident from notes from users from remote countries and companies. This electronic publishing revolution allows anyone with a personal computer and a modem to be a publisher will have far reaching effects on the structure of our society. Being a good digital librarian is a concrete way to create a future we all want to live in.
Posted inUncategorized|Comments Off on Ethics Of Digital Librarianship (1992)
I think this could be a 1 day exploration at least to figure out if it will work, but it is beyond my python ability.
Idea: OCR the labels of our 78rpm records, then take an image of a new 78rpm record and list the ones that are close to it. I would think this could be done with a search engine, or it could be with document vectors (gensim). On mac yesterday I got the images and a lead from trusty stackexchange:
pip3 install internetarchive
brew install tesseract
#get the images of the labels (there are 350k of them, but can test with 1000)
ia search "collection:georgeblood" --itemlist | head -1000 | parallel -j10 'ia download {} --no-directories --format="Item Image"'
ls -1 *.jpg | parallel 'tesseract {} {}'
# then something like gensim e.g. https://stackoverflow.com/questions/42781292/doc2vec-get-most-similar-documents
Anyone up for helping test this theory? Again, I am thinking this is a one day hack. If it works, then it will take tuning and such, and the Archive, I would hope, could sponsor that phase.
We have many duplicates in the collection already, so testing this could be easy.
An idea. Combine two things to solve a big problem: Solar Water Still and Greenhouse– greenhouse that runs on salt water.
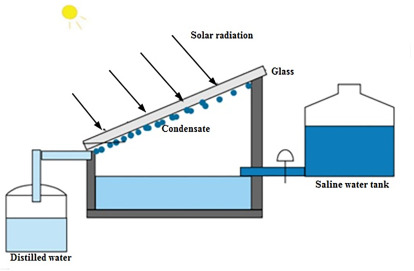
A “solar water still” is often a tent that has salt water at the base and captures the evaporated water and drains it into a bucket. Solar stills are “the simplest device that are used to obtain freshwater using solar energy as the sole energy supply”.
What if that tent were also a greenhouse, and the fresh water was used to water the plants? The plants could be in a raised bed that is above the pool of salt water that was under the full floor. This inexpensive construction would be decidedly low tech– low energy inputs, and low maintenance, but we would be growing plants using saltwater.
Then the Desalinating Greenhouse would be a hothouse that grew plants in the freshwater humid warm air and watered with the evaporated water. There would no complicated reverse-osmosis desalinization system or electric energy to drive it– just use salt water to grow freshwater vegetables.
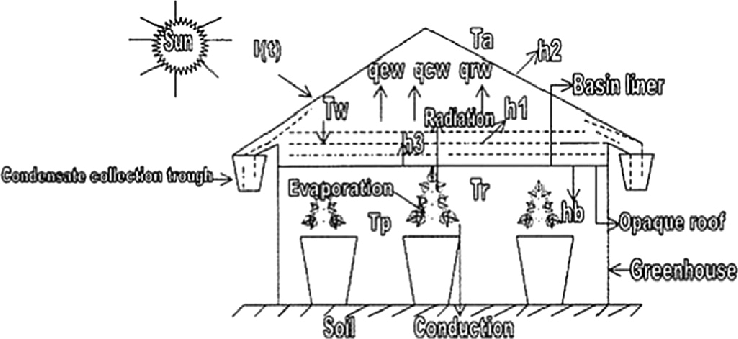
Generic Greenhouse that could be used as a large solar water still as well
Then we are using the sun to create the freshwater for the plants out of the saltwater. The salt water needs to be supplied and saltier water needs to be removed, but this is a simple pump if there is nearby salt water.
A Solar Still generates .06 gallons to .09 gallons (1/2 to 3/4 lbs) of water per day per square foot, and the peak water use in a greenhouse is 0.3 to 0.4 gallons of water per day. So we need maybe 2-3 times more salt water pool space than growing bed. This does not seem unusual in raised bed greenhouses.
This could be done anywhere there is salt water. Say coastal regions, on islands that are notoriously short of fresh water, and floated out in the open ocean (living the seasteading dream 🙂 ). You would need to pump the water to the greenhouse and return the more salty water, but this is low-tech.
Maybe we could grow fish in the salt water and get some aquaculture going. (This is not “aquaponics” since that uses the nitrogen from the fish to fertilize the plants, but since these are salt water fix, we can not pour that water on the plants. A freshwater pool with fish could be a fun add-on if things get mature.)
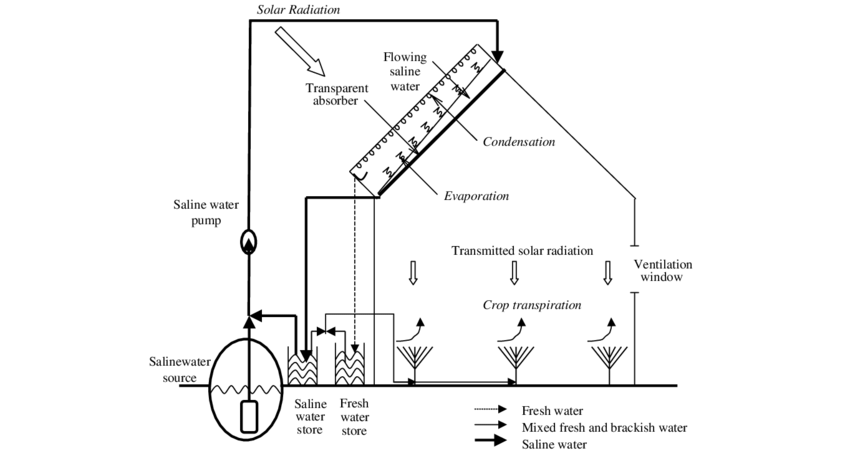
I bet this whole thing has been tried, as almost everything has, but maybe the coming crisis of fresh water will propel development. There is a paper about a similar system but seems more complicated than it needs to be:
A digital wave is upon us, changing our lives, our occupations, our family relationships, our sense of what it is to be a person. The Internet, as a technology, is playing a large role, but what its impact is and what it will be is little understood. I have been looking at the images people have made of the Internet and the concepts and metaphors used to describe it in order to see how people communicate what is happening. Largely, I have been disappointed in what I have seen. I do not think we have the language to process what is happening in a way that facilitates critical thinking and productive debate. While the individual ways we have portrayed the Internet are often descriptive of what is happening at the moment, maybe taken as a whole, or as a trajectory of portrayals, we might be able to see where the digital wave could lead—or should lead.
There is productive feedback between engineering and the imagination. To the extent that we can shape the Internet, what should that shape be? We imagine a future to engineer it, yet the products of the engineering process in turn direct and expand our imagination of the possible. What will the Internet become? An automated library? An indexed set of images? Video telephone calls? An immersive game? All of these were possibilities and all have now been realized. As users were introduced to these services, some dominant metaphors emerged to explain the novel experience of being online. I suggest these images are useful to track over time as it gives us insight into our evolving understandings and desires.
To that end, this is a timeline of metaphors and images we have made for the Internet, an evolution of sorts. As with biological evolution, eras overlap, as there were mammals during the time of the dinosaurs.
As a tour through history of imaginings of the Internet it might help us understand where we are going, and more to the point, where we think we should go.
Personally, in 1980, I imagined an Internet eventually centered on the computer, but useful powerful computers. Working in an artificial intelligence laboratory led me to think that computers will be increasingly autonomous and interconnected. To bring up these computers—in a way like offspring—I thought we needed a large number of people to interact with them and teach them, so they could learn from us. This in turn required that the machines be worthy of our attention. If we got there, there would be a merging of people, computers, and the library.
Those were the heady days of artificial intelligence, but the computers of the day were clunky accounting machines. So there were steps to go. A group of us built the fastest supercomputer of the mid-1980s to help build this vision of artificial intelligence, but even those computers could only hold dozens of digital books in their 32 megabytes of main memory. But this was a first step in teaching the computers by encoding books and newspapers. The goal was to have the machine search, find patterns, and make deductions by “reading” all books.
We wanted to bring the library to the computer, and the computer to the library. This longer vision, was just that, an unrealized vision. Whether it will turn out to be correct, only time would tell. Thirty-five years have now passed and technology and society has evolved, but the future and the proposals for the future are still unfolding.
Before starting the tour, I would like to point out an artist’s vision that seems to have missed the mark: WAIStation I and II by Nam June Paik in 1994 which used the name of the Internet publishing system I invented, WAIS. The sculpture is shaped to mimic a broadcast tower, but one made out of televisions and computer parts. I do not think this represents the interactive, participatory aspect of WAIS or the early Web of the 1990s. The vision is too centralized in comparison to what we imagined. But, it is interesting to see how others mapped the last generation of technology onto the emerging technologies and how visions are often wrong. I am reminded that our future may be foretold, but it is not inevitable.
Internet as Library
An aspirational image of the Internet came long before the Internet was built: that of a ‘Great Library.’ The dream of a reference collection that would be searchable and where footnotes could be instantly followed to other works. This idea blossomed into hypertext, Wide Area Information Servers, and then into the World Wide Web.
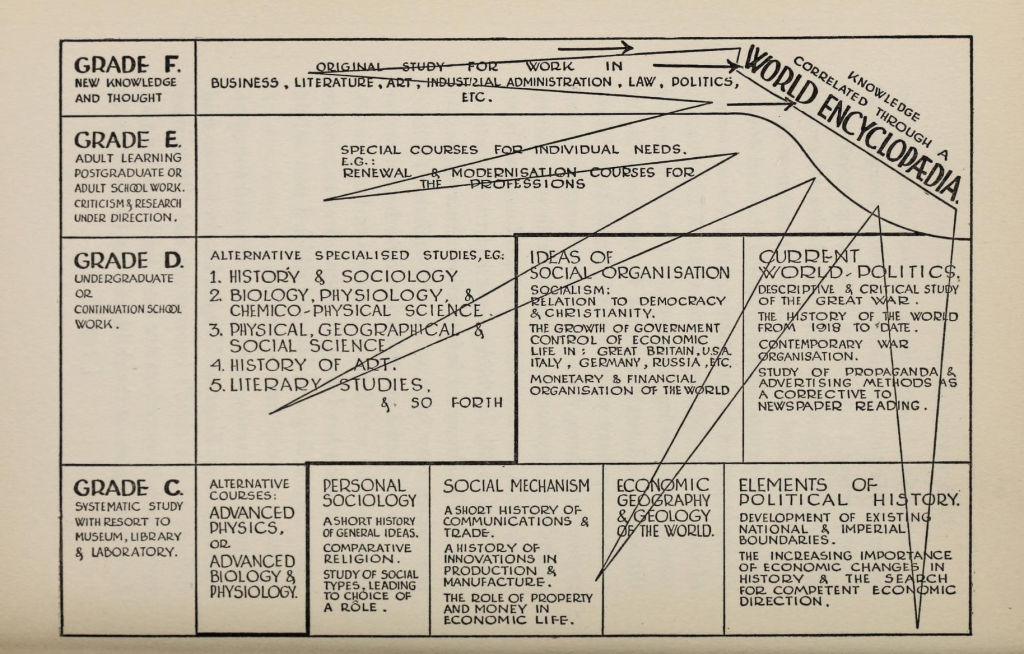
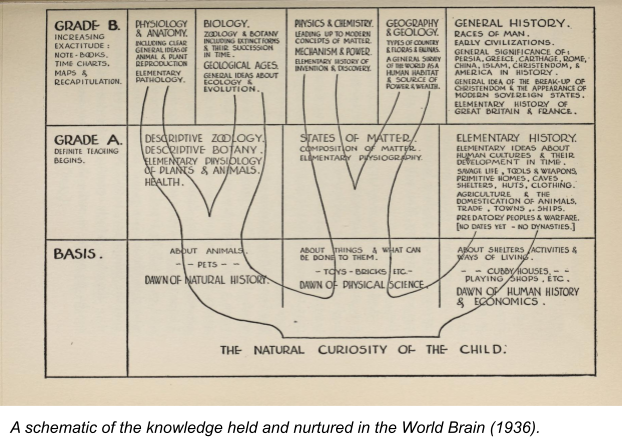
H. G. Wells’ collection of essays in 1936, World Brain, noted that “the time is close at hand when any student, in any part of the world, will be able to sit with his projector in his own study at his or her convenience to examine any book, any document, in an exact replica.”
For H.G. Wells, the resulting “World Encyclopaedia” would serve a political goal. “It might act not merely as an assembly of fact and statement, but as an organ of adjustment and adjudication, a clearing house of misunderstandings; it would be deliberately a synthesis, and so act as a [test] and a filter for a very great quantity of human misapprehension. It would compel men to come to terms with one another.” Such a resource would be comprehensive and flexible enough to match individuals’ intellectual growth. It would foster and enable education from the creative wonder of childhood through the technical and social needs of adulthood.
With such a comprehensive reference work, and the shared capacity to utilize it, humankind could realize the dream of World Peace, even as the political and economic engines of two world wars fast-tracked scientific progress in the name of industrial warfare. Interestingly, 65 years later, Wikipedia (2001) would come a long way toward realizing this vision of an encyclopedia built on the idea that a crowdsourced consensus would emerge on every topic.
The architect behind the U.S. government’s military research program in World War II—most notably of the Manhattan Project—also articulated the coming of searchable, comprehensive, and affordable knowledge. In a 1945 paper in The Atlantic, Vannevar Bush (as appeared) describes the “Memex,” a desk-sized contraption that was based on indexed microfilm. In such a system, “the Encyclopaedia Britannica could be reduced to the volume of a matchbox” and “a library of a million volumes could be compressed into one end of a desk.” In addition to the alphabetic and chronological indexing of a typical library, the Memex would enable associative indexing between documents through annotations and notes, thus better approximating the working of the mind.
The Memex was not, however, connected to computing power or network concepts1. As a tool, it was analog.
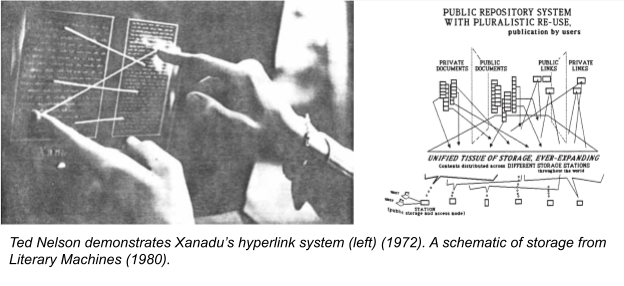
The great library idea was primed to go digital. Ted Nelson in the 1960s picked up on the idea of interlinked texts that began with the idea of living footnotes that illustrate the history and interconnections of ideas within our written canon. These concepts were beautifully illustrated in Literary Machines, as Nelson wove a narrative of the backend system that would support the future information networks he knew were coming.
“…there will be hundreds of thousands of file servers—machines storing and dishing out materials. And there will be hundreds of millions of simultaneous users, able to read from billions of stored documents, with trillions of links among them.
All of this is manifest destiny. There is no point in arguing it; either you see it or you don’t. Many readers will choke and fling down the book, only to have the thought gnaw gradually until they see its inevitability.
The system proposed in this book may or may not work technically on such a scale. But some system of this type will, and can bring a new Golden Age to the human mind.”
These images of a global interconnected library shaped the early Internet technologies of WAIS and the Web, even to the point where the inventor of the Web, Tim Berners-Lee called files of text “pages,” and leveraged some of the ideas of Ted Nelson’s hypertext in the development of links.
There have been many distinct projects to later realize this vision of a library on the Internet. The Google project, when at Stanford, started as a digital library project and was funded by the National Science Foundation’s Digital Libraries Initiative in 1994.
In this context, the Internet Archive, founded in 1996, was built to be both the library of the Internet and the library on the Internet. Its mission—Universal Access to All Knowledge—embodies the long defended democratic ideal of the public library as made possible by the networked reach of the Internet which allows the Archive to serve as a local library for users with a browser anywhere. The symbol of the Internet Archive is the Greek parthenon, with its reference to the Greek/Egyptian Library of Alexandria.
As the Internet has been adopted as a primary reference source for users everywhere, as well as a primary publication platform, there has been a questioning of preservation of ‘born digital’ materials.
Internet Archive artist in residence Jeremiah Jenkins wrestled with this concept of digital permanence in his piece “Browser History” (2017). In this work, he cast web pages into clay to make “cuneiform web pages.” He has buried several copies in different deserts around California. He asked “how to preserve the internet for a very distant future? The oldest clay tablets have survived more than 5000 years.”
If the library metaphor was as aspiration of the information that would soon be available at our fingertips, the early imagined model of service delivery was more limited. It was static, desk-bound, caught in a single computer, or tied to a central, vetted repository. As the Internet developed, however, we began to see collective knowledge as more networked.
Portraying the Network
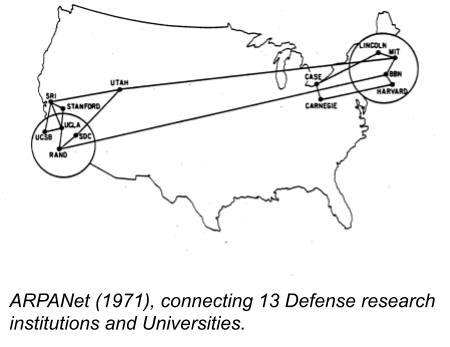
The ARPANet, the first network to implement the TCP/IP protocol, took “net,” derived from network, as its name. Early schematics illustrated the known nodes and the connections that bridged them. Because there were so few nodes, this was relatively simple. But it showed the new internet as a communications service connecting specific end users.
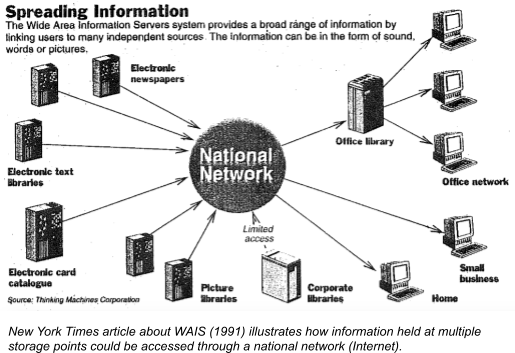
The network metaphor worked so long as all the nodes were known. But as more people joined and new services became available, the models of the Internet had to become more abstract. As the Internet started to be used outside of academia in the early 1990s, many images of the Internet were basic and functional, but helped bring a wider public to understand the technologies. Illustrations from New York Times describing WAIS in 1991 show how multiple sources of information held at multiple points could be tapped through a national network. The network itself, however, was a black box.
These services began to interact with one another in an ecosystem, and what took place within the national network began to be communicated. Writers, such as John Quarterman in his 1989 book “The Matrix” chose a matrix model for communicating the structure of the Internet. Others chose to list the services and demonstrate their relationships with simple arrows. Other diagrams grew to be cellular in their look, depicted on paper as colorful collages. NSCA Mosaic, which provided unified access to a set of Internet services including Web, WAIS, Gopher, and FTP, earned its name as a literal mosaic of integrated services.
2
As that ecosystem developed, both of networks and services, users began to experience a more integrated online world. But where was that experience taking place? As a 1994 network MCI commercial described, the Internet and its information “will not go from here to there. There will be no more there. We will all only be here.”
But where was here? McLuhan predicted a “global village,” but in the early 1990s the Internet was being described as a mysterious space.
Internet as Cyberspace
“Cyberspace” is a metaphor for the Internet made popular in the early 1990s. This definition from a 1993 proto-Wikipedia says “The word ‘cyberspace’ was coined by the science fiction author William Gibson, when he sought a name to describe his vision of a global computer network, linking all people, machines and sources of information in the world, and through which one could move or ‘navigate’ as through a virtual space.”
This captured the idea of a place or space, but of a different kind. Bruce Sterling in 1992 described our first experiences of cyberspace as tied to the telephone. “Cyberspace is the `place` where a telephone conversation appears to occur. Not inside your actual phone, the plastic device on your desk. Not inside the other person’s phone, in some other city. _The_place_between_ the phones. The indefinite place _out_there_, where the two of you, human beings, actually meet and communicate.”
John Perry Barlow, before 1992, said “Cyberspace is where your money is.”
This cyberspace was markedly different from the networked metaphor. The emphasis was no longer on the nodes, but on what happened between them. Cyberspace was distant, not of this world. It was big, star-studded, traced and defined by the movement of ideas and information.
Just as in the original 1960s Star Trek ventured into “Space, the final frontier,” cyberspace was to be explored by brave, cutting-edge adventurers who could log in.
Carl Malamud wrote a book in 1993 titled “Exploring the Internet: a Technical Travelogue.” The book was researched through interviews around the globe with the engineers and thinkers actively building the Internet. I am proud to be in it. The book captured the sense of adventure inherent in discovering and building a new place.
After the first major Internet interface program, NSCA Mosaic, came to be called a “browser,” the next browsers embodied this metaphor of exploration directly. Netscape Navigator’s logo (1995) placed the user at the helm of a ship steering among the stars. Microsoft’s Internet Explorer (1995) holds the ‘explorer’ word in its name, and Apple’s Safari (2003) also signifies adventure and has a logo of a compass.
Cyberspace was increasingly populated with explorers, laypeople, and the now native hackers who viewed it as their primary intellectual home. In the 1996 Declaration of the Independence of Cyberspace, again from John Perry Barlow, he warns “Governments of the Industrial World, you weary giants of flesh and steel, I come from Cyberspace, the new home of Mind. On behalf of the future, I ask you of the past to leave us alone.”
Made visual, there were many maps made of “Cyberspace” as the interconnections were visualized in artistic renderings. A swirl of relationships was colored and mapped, but unlike the early network schematics, the emphasis of these renderings was on the interstitial place between the nodes, the new virtual place where everything happened.
The peacock map posters became a staple of classroom and dorm walls. The earliest of these renderings, from 2000, is a visual not unlike the early universe just after the Big Bang. Matter is not yet organized. The 2003 Opte Project, digital artist Barrett Lyon’s open source project to visualize the metaphysical space of the Internet, shows the formation of large scale structure within the web as it expanded. The artwork was later featured at MoMA.
That structural formation was further depicted by the 2016 Internet Archive Webverse project, an interactive version of cyberspace rendered by Owen Cornec and Vinay Goel for the Archive’s 20th anniversary. In this portrayal, the universe is made up of websites as stars, and the distance between the stars, was made by the number of interconnecting links. This visualization highlighted “galaxies” centered around Yahoo, or Facebook, or the somewhat separate constellations of Chinese and Russian websites. Cyberspace, and our understanding of it, has become vast but somewhat structured.
Settling the Electronic Frontier
At about the same time as the “cyberspace” image, there was a related, but interestingly different metaphor for the Internet as the “Frontier,” as located on land, albeit wild land. The Internet was now real estate, and we were homesteading it. The technical language of the components also changed. WAIS and FTP had “servers”, while the World Wide Web had “sites.”
The Electronic Frontier Foundation was founded in 1990 to defend the civil liberties of those participating in, working on, and communicating in the new digital media landscape.
On the frontier, rules were being made by these new communities. Just as individuals had long trudged toward physical frontiers—from the Western United States to Australia and the Russian far east—to build a new life, to recreate their identity, to realize a utopia, or otherwise find fresh inspiration from the tradition-bound cloth of the old world, there was a mass migration to the Internet, provoking many experiments in governance.
Here there was a tension, always, between the utopians—the ‘open world’—who wanted to build a new form of community online, the resource capitalists who wanted control of the metaphorical real estate to support their businesses, and the less nimble governments. The frontier was where these actors interacted as the norms, law, and values of the Internet were first forged.
As example, ‘moderators’ of chat rooms imposed order on those within their ‘boards’ and ‘rooms’. Services evolved rules of behavior with takedown and other policies enforced by ‘admins.’
Anonymity added a key dimension to this sense of freedom, as individuals could choose an identity distinct from their day-to-day identity. They could choose more than one identity even, if they liked. Roles were fluid and experimental and, at first, separate from the flesh and blood person “IRL” (In Real Life). As a famous New Yorker cartoon from 1993 put it: “On the Internet, nobody knows you’re a dog.”
But as the frontier was populated, the real estate was fenced off and guarded. This process encouraged a remarkable amount of investment in the Internet, both from the private and public sectors.
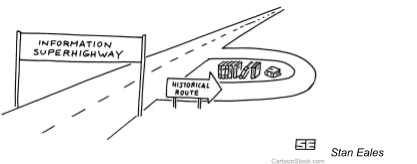
As a landed metaphor for interconnection, Al Gore popularized the concept of an ‘Information Superhighway’ to encourage a network that was not privately owned as part of his legislative push for the High Performance Computing Act of 1991. In doing so, he codified what was to become another long-running metaphor for the Internet.
The superhighway would connect people and businesses through a virtual road system, open to carry any information for anyone. The language of highway infrastructure translated well in Washington, D.C., as governments were then comfortable with their role in financing and building basic infrastructure. This superhighway was never realized in whole due to intense lobbying by cable companies and other entrenched private interests.
This metaphor, as the Stan Eales3 cartoon depicts, shows how conception of the Internet had, for the moment, forgotten its roots as a digital library, with the curation and publications standards traditionally associated with print authorship and canonical knowledge. The types of information traveling along the superhighway would be a much broader swath of human experience.
The language of roads became increasingly useful in proposing the role for cable companies and Internet Service Providers in this new land. As their power consolidated, the metaphor has easily lead to conversations of possible “speed limits,” “tolls” “on and off ramps,” and “fastslow lanes.”
With the metaphor of the Internet as real estate which could be settled, propertized, built upon, and fenced off, Larry Lessig coined the term “Creative Commons” in 2001 to represent a form of open space, or park, for parts of our virtual world.
Surfing the Web
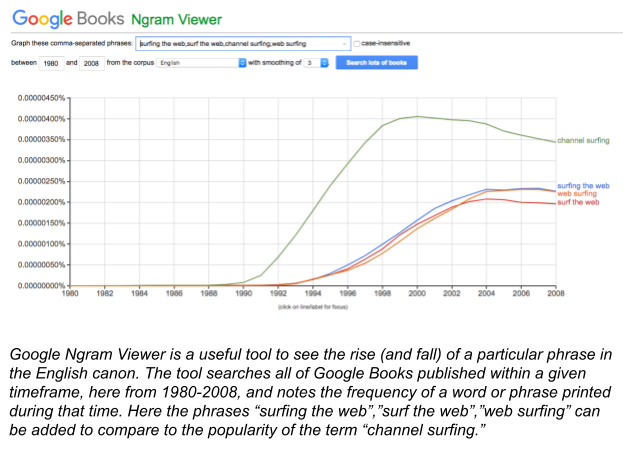
“Surfing” the World Wide Web, a common expression by the mid-1990s, is not a landscape image but rather an expression of what it feels like to use the Internet. In this image4, the Internet and World Wide Web were not places to explore, but rather a sport you played. The Internet was an activity, an experience.
The phrase was derived from ‘channel surfing’ on cable television, but by the year 2000, use of the phrase to describe using the web overtook its television use.
A key attribute to this metaphor, however, is what it indicated about the ratio of reading and writing on the Internet for most people. Although publishing systems existed for non-technical users—the term “blog” entered the lexicon in 1997, LiveJournal was launched in 1999—the term surfing represented the average user as shredding sportily atop the information wave below, rather than contributing to that wave or living in the ocean. Authorship was still more formal, and most users were consumers rather than participants in the creation of knowledge or content. Moreover, surfing was not a continuous activity. Just like surfers on the California coast, users would surf the web, hang up their digital wetsuits, and return to everyday life.
But another digital wave was on its way that would significantly shift the way the Internet was imagined. As the Google Ngram viewer shows, the surfing metaphor peaked in 2004 just after the rapid rise of first Friendster, then MySpace and the founding of Facebook in 2004. As social networks became popular, the experience of being online was about to become immersive. New metaphors were needed, lest we drown.
The Facebook
In Star Trek, the Next Generation, a new alien being was introduced— “the borg.” The borg was made up of people augmented by technology that networked them into a single large being. This global brain was not a hero, but a villain. The borg worked as a collective hive-mind, augmented with ‘artificial intelligence.’ While separate beings, there was no individuality amongst the members of the borg. From the cradle, the borg’s young were always connected via implants glued to the side of their head. A famous line from the borg is ‘resistance is futile.’ The interconnected world could not be escaped.
Cell phones, which became widely used in the 1990s, allowed people to stay connected. First they were connected with voice and text, and in the 2000s with pictures, video, the Internet, and social sites5. With the wide adoption of cell phones, the expected response time to a message shrunk considerably. In fact, for younger people the social expectation was that one had to be responsive immediately. To meet this expectation one had to stay connected. One had to be always on.
Furthermore, by moving to cell-phones the Internet services like Facebook were often no longer anonymous. Your real-world identity was now exposed and interconnected; reputations online and off were now tied.
Increasingly, people became “glued to their phones” as the apps incorporated news, camera, and chat functions and the phones became widespread.
It may be a stretch to relate Star Trek’s ‘borg’ and the rise of the always-on cell-phone Facebook feed, but the timing aligns. While introduced in 1989 the borg became, by TV guide’s 2013 user poll the 4th favorite villain, possibly reflecting a level of anxiety during that period of loss of identity through always-on interconnection of the rise of the smartphone at the same time.
As this always-connected reality became commonplace some artist’s depictions shifted from being negative and borg-like to becoming matter-the-fact. In Sherlock (2011) and Nerve (2016), talk bubbles and apps became visible parts of movies. The Internet, in these depictions, has come to surround us, to augment us.
As voice commands with our phones started with Siri in 2010, then acquired by Apple and now always-listening home assistants (Amazon’s Alexa in 2014, and Google’s Home in 2016), people are interacting with the Internet in more intimate ways. Movie depictions of assistant robots such a Real Human (original Swedish version 2012) are coming to be more day-to-day than the threatening “others” of Blade Runner (1982/2017) or Westworld (1973/2016).
Algorithms
In the 2000s, the Internet services developed into “platforms” such as Facebook (2004), YouTube (2005), Instagram (2010), Twitter (2006) that were multifaceted digital environments optimized by algorithms designed to hook users through individually tailored content. Now, some fear these algorithms are running us—telling us what to do, what to think, who to vote for.
A brilliant video from 2004 predicted the rise of algorithms in creating personalized information ‘bubbles’ in a fictional future system called EPIC that, by 2014, has taken over the media landscape. It is worth quoting at length:
“EPIC produces a custom content package for each user using his choices, his consumption habits, his interests, his demographics, his social network, to shape the product.
A new generation of freelance editors has sprung up. People who sell their ability to connect, filter, and prioritize the contents of EPIC. We all subscribe to many editors. EPIC allows us to mix and match their choices however we like.
At its best, edited for the savviest readers, EPIC is a summary of the world deeper, broader, and more nuanced than anything ever available before.
But at its worst, and for too many, EPIC is merely a collection of trivia, much of it untrue, all of it narrow, shallow, and sensational. But EPIC is what we wanted. It is what we chose. And it’s commercial success preempted any discussions of media and democracy, or journalistic ethics.”
This video, as a piece of art, utilized newsreel-style matter-of-factness to describe one potential future that viewers in 2018 may find eerily familiar. As traditional journalism was swamped by a wave of free, or seemingly free, content from blogs—often less well researched, more opinion-driven, and less guided by journalistic ethics—the way consumers got news shifted markedly. The U.S. presidential election of 2016 supercharged this conversation as fake news, hyper-targeted ad buys, and big data analytics were applied to selling candidates and stories. While this prescient video from 2004 could have informed the evolution of technology, I fear it did not in this case. The video itself has not been widely cited since its introduction in 2004.
The power of algorithms to control us is featured prominently in the previously mentioned movie Nerve (2016). In it, teenagers are lead by their phone apps into dangerous situations. The interesting twist in this depiction is the phone apps are completely driven by other users and crowd-written software algorithms. In such a world, who can be held responsible? The individual is hostage to the whim of the crowd. We, the collective, are the ones driving this based on a mixture of technology, networks, and anonymity.
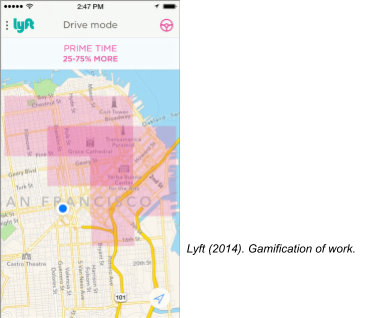
Feeling “gamed” is spreading. Uber and Lyft have automated surge pricing when their analytics identify a supply and demand imbalance in a particular area. When a threshold is tripped, their programs automatically incentivize drivers to go to certain areas or drive at certain times of day. These algorithms force their drivers into characters in the form of a game. I asked a driver, point blank, as he talked about getting some reward for working an extra hour, if he felt ‘gamed’ or ‘played.’
He answered, ‘absolutely.’
Consciousness of being surveilled by companies and governments is growing, sometimes to improve the “user experience” and sometimes to control a population. This growth of mass surveillance was not always obvious. In 1985, David Byrne sang “In the future there will be so much going on that no one will be able to keep track of it.” He was right that no person could keep track of it, but machines can, and increasingly are, keeping track. Building a profile of billions of people is not a difficult task at this point for companies or governments.
Rendering the effects and possibilities of Big Data and algorithmic “deep learning” in artworks and language that most people can understand is in early stages of evolution.
Machines Viewing Us
Where is this going? What can we say about what comes next?
Trends that are emerging include decentralized systems such as bitcoin and the decentralized web, immersive virtual reality games, and augmented reality. Creative imaginings are starting to emerge.
One of these emerging trends that I would like to highlight is the switch from imagining what the Internet looks like to people, to how people look to the emergent machines.
In this depiction, the Internet is not being explored by us, not being controlled or surfed by us, or even controlling us, but rather the machines, that make up the Internet, exist on their own and learn from the world. This is a view that while the Internet needed us to bring it up, it will soon not need us, and will, in fact, outgrow us.
Trevor Paglen created an eerie and beautiful piece with the Kronos Quartet in 2017 in which while the audience watched the string quartet perform, the machines did as well. The machine started by figuring out where the performers were and what they were doing. As the concert progressed, the machine decomposed the images it saw and analyzed them in real time. Computers interpreted the images, using algorithms to figure out if the performers were sad, what they were holding. Displays projected the machine’s interpretations of what was happening, so that the humans in the audience could see what the machine was thinking and how it reacted to the musicians on-stage.
Wired Magazine called it unsettling and indeed it was. For perhaps the first time, a human audience sat alongside an artificial intelligence audience, both interpreting a string quartet performance. Sitting side by side with the machine, the humans were no longer in control, but nor was the computer trying to control them. The computer, in this artwork, is there to watch and enjoy the performance.
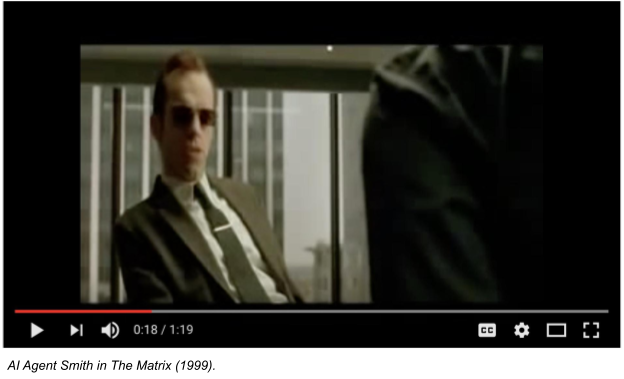
Other artworks depict what the Internet has come to think of people. Notably in the Matrix (1999) where the networked Artificial Intelligence, Mr Smith, says:
“I’d like to share a revelation that I’ve had during my time here.
It came to me when I tried to classify your species and I realized that you’re not actually mammals. Every mammal on this planet instinctively develops a natural equilibrium with the surrounding environment but you humans do not. You move to an area and you multiply and multiply until every natural resource is consumed and the only way you can survive is to spread to another area. There is another organism on this planet that follows the same pattern.
Do you know what it is? A virus. Human beings are a disease, a cancer of this planet. You’re a plague, and we are the cure.”
The AI, in this rendering, calls us out for our moral shortcomings.
Or in 2001, a Space Odyssey (1968) depicts briefly how we might appear to HAL as the crew is confronting HAL about an error. It is a fish-eyed view of us, but one that engages perceptively the crew as they go about their task.
A much longer scene at the end of the movie is a shot of the spaceman when he finds himself is in a sterile white room, presumably on Jupiter. This room might be thought of as a kind of cage in a zoo, where the spaceman is given what he needs to live but is contained. One shot in the movie has a view looking down on the man and the room from a surveillance camera-like angle. Humans ending up in a zoo tended by a higher being is certainly one view of how the Internet and Artificial Intelligence can evolve.
Danny Hillis, my mentor, as we were working at Thinking Machines in the early 1980s often said, “We want to build a machine that will be proud of us.” We were bringing up the next generation. In my conversations with Carl Feynman at that time, we thought if we were going to be bringing up our new overlords, they should at least read good books. While not of the Internet yet, the computer we were building did share the recognition of the importance of the network, of the interconnections, of the links. The machine we were building was called the “Connection Machine” where the connections between the processors were seen as important as the tens of thousands of processors themselves. The difference between this machine and the Internet was that these processors were not yet spread around the world.
This imagining of a machine’s view of us, a machine that is distinct from us, a machine that has evolved beyond us, brings me around to my original ill-formed vision in 1980 of what I could help make the Internet become: a network of people, the library, and machines. I did not see it in a light glorifying or terrifying, but rather as a major inevitable project that could be built well or badly, and I could help build it well. In that way it could be a major positive step forward.
1A later book by Noah Wardrip-Fruin brought together many of these early imaginings of medium to come and was summarized in the introduction, Janet H. Murray: “The engineers draw upon cultural metaphors and analogies to express the magnitude of the change, the shape of the as yet unseen medium. The storytellers and theorists build imaginary landscapes of information, writing stories and essays that later become blueprints for actual systems… Gradually, the braided collaboration gives rise to an emergent form, a new medium of human expression.”
3 Cartoonist, Stan Eales replied to our inquiry, “In response to your question about how I came to draw the cartoon… well, I suppose I wanted to show that the internet has superseded traditional knowledge, just a a superhighway/motorway/ autobahn supersedes traditional, meandering roads. While the new route may take us places fast, the sheer speed of travel means that we will miss things along the way. Do we risk eroding critical thinking in favour of speed and quantity of information. But are we able to process all of the information coming at us? Is the internet too fast; built beyond the capacities of the human brain to assimilate and process information.
But, the cartoon can also be seen the opposite way. For those who wish to get off the superhighway, the traditional, old fashioned means of getting information are still available. Despite the domination of the internet, people still read books, they still go to the cinema, they still listen to the radio, they still have real sex rather than virtual sex. Despite the domination of fast food, people still make home-cooked food. There is room for everyone. Cinema didn’t die once television was invented. The ‘information superhighway’ is just a tool. It’s how you use it that counts. If you are a speed freak and depend on it from getting everywhere, then you risk losing out on some of the finer points in life.”
5 The Apple iPhone was introduced in 2007, and by 2012 ‘smartphones’ dominated more than 50% of the mobile phone market. With the iPhone came the rise of ‘applications,’ or more simply ‘apps’. The Facebook was introduced in 2004, mobile support came in 2007, and a dedicated app in 2008 with the launch of the Apple’s App Store for iPhone.
Posted inUncategorized|Comments Off on Imagining the Internet: Explaining our Digital Transition
One of the goals of a new World Wide Web: the Decentralized Web was to help people make money by publishing on the web. There are approaches to this such as Coil, but the vision in the paper has not been done. The idea was to be able to post a file to the DWeb and then have people pay for it and then unlock it, all without a central authority. Decentralized payments on the decentralized web. Not only has it not been done, it may not be possible… until now (maybe).
Here is the scenario I could not figure out: Can my son make a decentralized website for his new album where one of the songs is free, but the others cost something? Sounds easy– you post the first song unencrypted, and the others encrypted. Then if you put a bit of bitcoin or ether or something in a slot, then you get a key to the encrypted files. Yes, you could then unencrypt the files and then post them again, thus making a black market for the files, but that is hard to avoid without DRM and that has its own problems.
An existing way to do this is to host your files on iTunes or Amazon and they will deliver unencrypted copies to those that pay. This works, but it puts lots of power into the hands of those websites. In fact, those companies have gotten very rich doing this service for people.
Can we have a decentralized way to distribute keys based on some event on a blockchain? This has been frustrating, but the answer, so far, seems to be No. The reasoning is that in a centralized system, one would go to a website, make a payment or prove you made a payment and the website would send you a key to unlock the files. The website would makes sure the payment was made, and send one and only one key based on that payment to the purchaser. Ok, some of these pieces are understandable how to do in a decentralized way. It is possible to post the payment on a blockchain with a public key of the purchaser, so the vendor could the use the public key to protect the decoding key so only the purchaser gets it. So far so good. But, there has to be a vendor that can issue the key, therefore the vendor has a secret that should only be shared or used when issuing a key.
This works when the secret is in one place. But if the code for issuing the key were on a contract-based blockchain such as Ethereum, then anyone could see the code and get the key without paying. You could even have the secret in several places, and ones that are distinct from vendor– think escrow agents, but that is klunky work-around.
So you say, what is the breakthrough? Well, I read a piece about some cryptologists having discovered the “Crown Jewel of Cryptography” that may make this possible.
For example, suppose you have a program that carries out some task related to your bank account, but the program contains your unencrypted password, making you vulnerable to anyone who gets hold of the program.
Their system allows that program to be distributed with an encrypted version of the password to be used in all ways like the one with the unencrypted password, thus solving the problem.
To put in the our example: the program that issues keys to the music files can be distributed to anyone and they can not find the internal secret because it is encrypted. But, you say, then anyone can run that program and generate the keys to unlock the music files so people do not need to pay. But this is where I hope the contract systems in blockchain systems comes in (but I could have this wrong). I am hoping that the program also has a test to check for an event happening on the blockchain, such as a payment is made, then when the program is triggered and proceeds to encrypt the music decoder key with the purchaser’s public key. The purchaser can then use their private key to unlock the message and get the music decoding key. The purchaser rocks out to the music and my son gets paid.
I do need help in understanding if this if contracts can do this: when an event happens on the block chain, then a piece of code is triggered to run successfully. If that event did not happen on the blockchain, then the program would not run successfully.
If I understand these two pieces, the “Crown Jewel” and blockchain contracts, then we can make DPayments on the DWeb work.
And that is a major step forward!
Posted inUncategorized|Comments Off on DPayments on the DWeb now possible? Math breakthrough
The Internet Archive has over 90 employees in the United States, but they reside in 17 different states and even more counties. While distributed workforces are becoming common, it has become so painful to deal with the federal, state, and county regulations that we will soon be paying to outsource the headache. We are not the only ones straining under the burden, but there are some possible fixes.
Hiring in Canada is easier and less expensive than in the United States, meaning that the federal government, each state and many counties should make changes to become competitive.
The real reason the US and states should make changes is to make a better home for their residents, but some will be motivated by making it a better home for businesses. Luckily, changes would benefit both businesses and individuals.
The rules might have made sense at a different time when companies hired many people in one location. But they do not make sense now– now that more organizations are becoming distributed. The non-profit organizations I work with are struggling with this issue and many are looking to outsourcing organizations of different flavors to deal with our governments.
The problems start with a lack of universal healthcare. If we did not put this administrative burden on companies and nonprofits, it would greatly ease hiring employees. It is not just the expense for the insurance– it is all the administration, yearly rebidding, managing many plans, and across the whole United States. Many people that do not want universal healthcare say they are “pro-business,” but in fact it is hurting United States businesses and families. It is hard for me to understand.
Then there are state regulations– if we want to hire a person in a new state, or someone wants to move to another state, then we have to register to do business there. Every state has a different unemployment rate as well as a different base rate to be taxed on. We also have to do seemingly endless forms and audits for workers compensation and taxes. And some counties or burroughs have their own regulations and taxes. A national payroll service helps (which is costly, by the way) but the screams of agony from the HR department for other administrative tasks have been growing over the years. We often do not hire someone because they lived in a state where we did not already have an employee.
Then there are some bizarre regulations, like the definition of employee versus contractor. We may want to hire someone to work a few hours, but this can be too hard in California because of the expansive rules. This is being debated now in the case of Uber and Lyft, but let me give a different, recent, and real example.
I help support a five-person arts organization that pays teachers to teach specialized crafts. Some of these teachers work only a few hours a year. At first they were contractors, but then one of the teachers applied for unemployment to the state of California which then launched a disruptive investigation and found every one of these teachers were employees in their eyes and fined the organization tens of thousands of dollars. The level of paperwork now required to have someone work for 2-3 hours per year is absurd. And many of the teachers were mad because they did not think of themselves as employees nor want to be. Lets figure out the benefit we are trying to achieve and go straight for it rather than the catch-all system that often does not fit our current environment.
Another bizarre regulation is that a nonprofit has to register to raise money in each and every state if they put a donate button on a website. Each state is bizarrely different. There are firms that outsource this registration function which is a tax on our non-profits. This is dumb. States should not penalize nonprofits in this way.
What should the United States do? Universal Health Care. Universal Retirement Accounts that are not attached to companies. In general, stop assuming we are living in factory towns with employment for life, and therefore change the regulations to reflect our current world.
What should states do? How about uniform regulations for companies with fewer than 50 employees in a state before jumping in with non-standard regulations? One uniform regulation for all small businesses could be defined and state legislatures could adopt. Then states would have the incentive to adopt the uniform rules for small businesses in order to be attractive to small businesses which are becoming increasingly distributed.
Distributed organizations are becoming more common– lets not penalize those that want to hire United States residents.
Posted inUncategorized|Comments Off on Hiring Americans is hard for distributed organizations: How the federal and state governments can Fix It
What would it take to make an app that would work like Uber, but without the corporate entity? And without the high percentage that goes to Uber. Hum… Let’s take some of the needed parts…
Hailing a driver: a rider wants to know the driver is safe, closest, and the price.
On the safety issue, let’s suppose a really good reputation system (see below).
“Closest” can be done by integrating a good map app (see below).
And a price– this could be as simple as a set function of per-ride, per mile, and per minute.
Paying a driver: could be as easy as crypto/bitcoin being paid part as the ride starts and the rest as it ends. But there could be more complicated parts of this where there is a 3rd party that takes a bit, that may pay the app developer (see below). If there is a 3rd party, don’t we have Uber? Maybe, but could be much lighter weight. There are also contracts in ethereum that could help with arbitration in the case of disputes.
A reputation system: Seems we need a strong reputation system. Yelp, it has been said, has been corrupted, and it is difficult to avoid this. Reddit? Slashdot? Maybe a mixture of up-vote/down-votes from anyone, and mixing in social network to favor your friends, or maybe subscribing to aggregators of reputations…
Map App: Google has nailed this, but I bet a rideshare app puts lots of load on it. We might need a per-ride payment to go to the map provider.
Price and payment: could be one price per ride, and this has advantages. What if a rider could pre-tip, or a driver could pre-discount? That might help those that do not have good reputations yet. Does a rider pick between drivers, and vice versa? Since bitcoin is not widely used yet… how about google/apple pay? Venmo? Paypal? Some of these have evolved pretty anonymous payments.
Evolving the app: what if there were many apps competing for the riders and drivers– what if it evolved into a system where the apps were somewhat compatible so a driver could run many apps at once and they would compete for her business. Then the apps would need reputations as well, and they could evolve different algorithms. Does the app provider get a piece of the action?
If this could work, it could mean rapidly evolving ecosystem with many players at every level.
It could go very wrong– a great movie that shows this is Nerve (worth watching). It could be used for escort services and other match-making functions.
Anyway, I like the mental excersize of ______ but decentralized, where _____ is your favorite cool thing. Google Docs, Tesla, Slack, WordPress, Internet Archive…